Introduction
Machine learning is a subset of Artificial Intelligence.

Traditional Programming
But before we dive deeper into what that means, we will take a look at “traditional” programming:
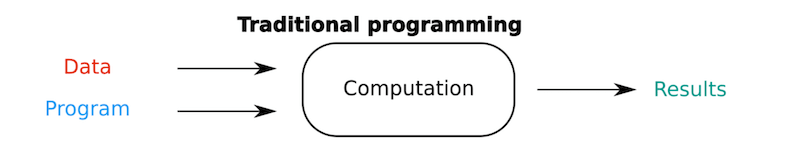
In traditional programming, a programmer/analyst/designer creates a program that manipulates data to get to a result.
As a concrete example, let us look at a money transfer in a banking app.

The analyst knows exactly which actions need to be performed to successfully transfer money from Alice to Bob:
- authenticate the user
- fetch her account(s)
- check the balance
- …
- get all the details for the money transfer
- successfully wire the money to Bob.
To achieve a successful money transfer, the programmer programs the exact sequence of steps and data manipulations for the computer to perform.
Machine Learning
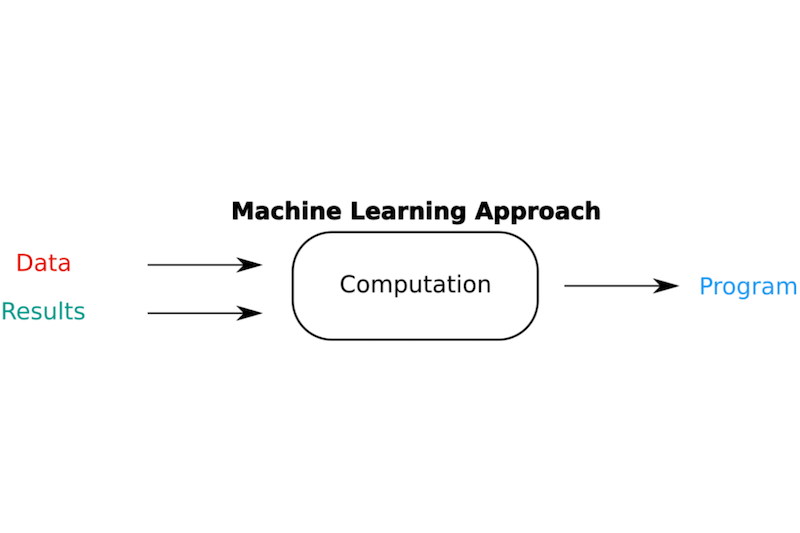
In machine learning, however, we will use the data, to produce a ‘program’ that is able to create an output from inputs it has not seen before, by learning relationships in the data.
Let’s read that again:
- in machine learning
- we use data
- to learn relationships
- which produce a “program”
- that is able to take inputs it has never seen and create an output.
Here is an informal defintion:

This gives you a bit of an idea.
Here is the formal definition:

If you had to read that formal definition a couple of times and it still makes little sense, that is more than ok.
To make it more digestible, we will have a look at two examples:
Example 1: playing checkers

If we want to have a computer play checkers (=task) then the more the computer plays (= experience), the better it should become at winning the game (=performance).
Example 2: recognizing cats

The same goes for recognizing cats in pictures (=task). The more the ‘program’ looks at pictures of cats (=experience), the better it should become at recognizing whether or not there is a cat in the picture (=performance).
Some common tasks
In machine learning, there are some common tasks:
- regression
- classification
- extracting knowledge
- recommenders
- generation
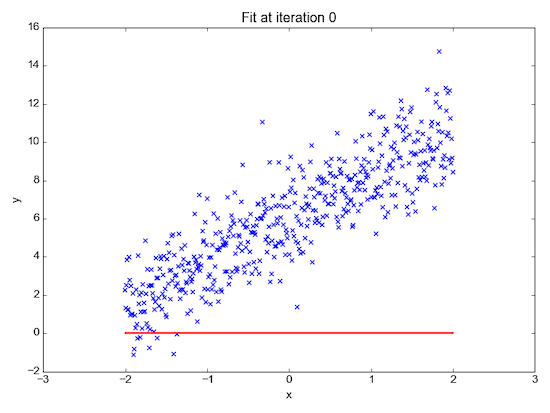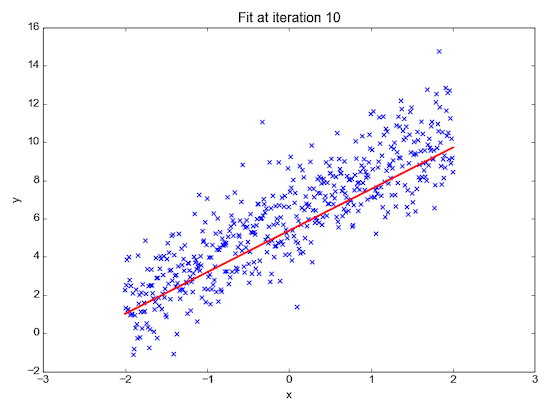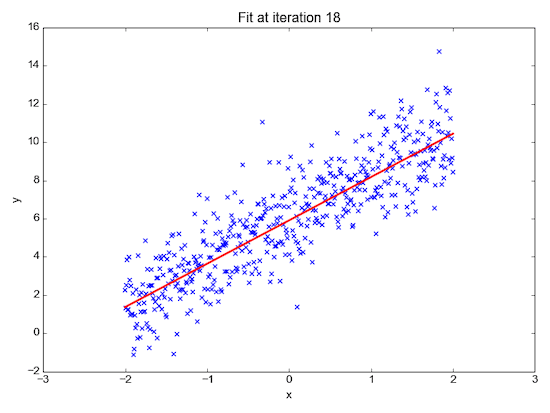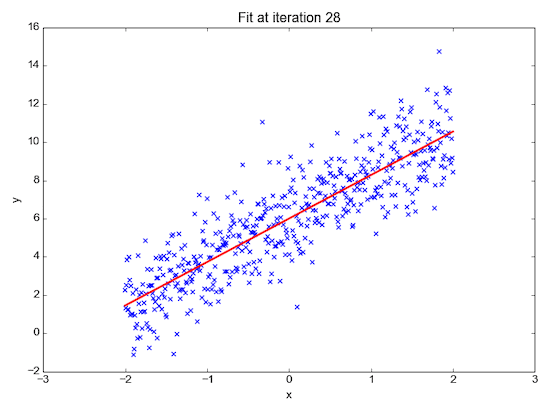
Regression: predict a value
With regression we try to predict a value given a number of inputs.
For example:
- given the day of week, temperature, and chance of rain: how many ice creams will be sold?
- given the size, location, and type of real estate: how much is it worth?
- given the time of day and type of post: how many likes will a post receive?
Classification: predict a class
With classification we try to predict to which class an input belongs to.
For example:
- is an incoming email spam or not?
- is a credit card transaction fraudulent?
- is tumor malginent or benign?

Extracting knowledge
Knowledge extraction can be used to extract structured data from an unstructured input.
For example:
- for text: get the name, birth date, nationality from a Wikipedia biography;
- for images: locate and label all cats.
Recommenders
Recommenders are used to make content or product recommendations based on similar content or products, or based on what others like you have enjoyed.
For example:
- a list of Netflix shows to watch after finishing the last episode;
- given your preference for romantic comedies, a list of what other people with that same taste enjoyed.
Generation
Generative models create entirely new content, sometimes based on some user input.
- given a few words, write an article or story;
- generate new images that you can use on your site.
Common techniques
Decision Tree
One way to classify inputs is to create a decision tree, which, by using a set of “if-then-else” evalutions, guides you to which class an input belongs.
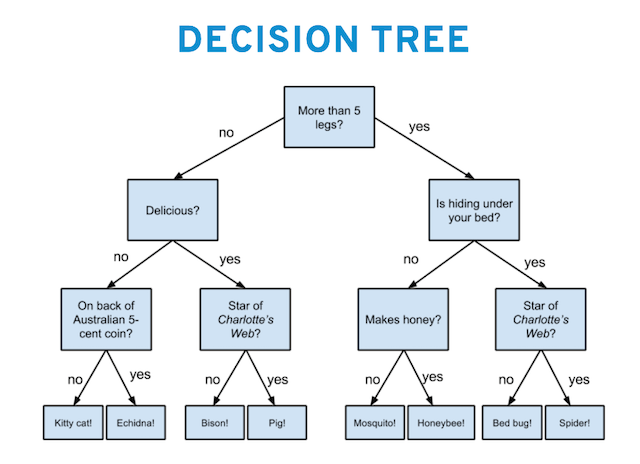
However, instead of crafting it ourselves, we have a computer learn it (construct the three itself) from examples.
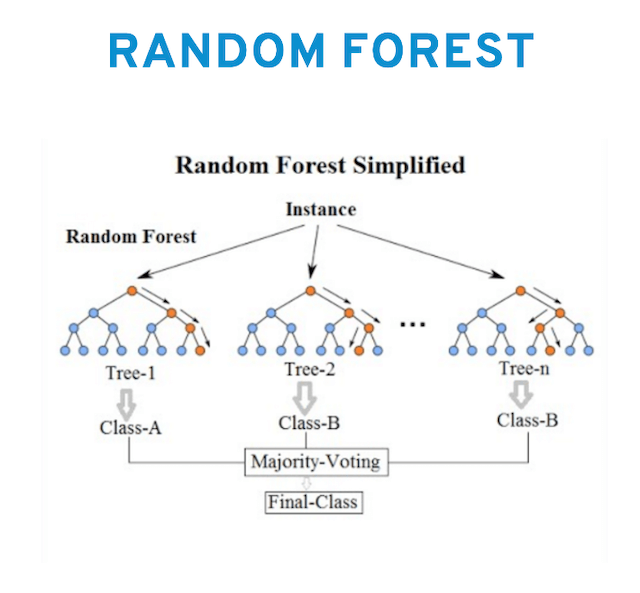
Random Forest
If we combine a number of decision trees, we get what is known as a “random forest”.
The program learns multiple decision trees to make a suggestion for the output (class or value) and in the final step we use a way (“voting”, “averaging”,…) to combine the results of individual trees to one final output.
Neural Networks
A technique that won a lot of attention the last few years - although the idea has been around for decades - is “neural networks”.

In essence a neural network builds a mapping
from inputs
- an image
- text
- numerical data
to outputs
- “malignent” or “benign”;
- “spam” or “not spam”;
- 74 ice creams sold;
- a product recommendation;
- a newly created image.
In a lot of introductions to “neural networks” you will find they are modeled after the brain, and then show you the picture below:
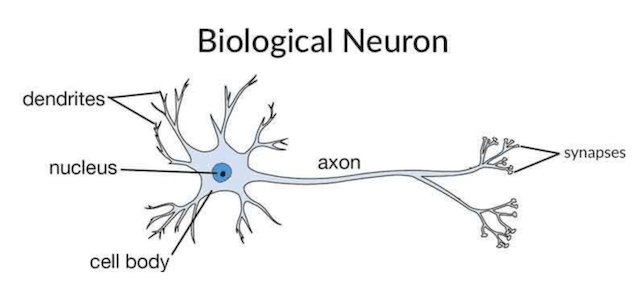
The only thing this image is trying to explain, is that our brain is made up of neurons that:
- take inputs;
- do some form of processing;
- produce an output.
And that is basically the end of the comparison to our human brain.
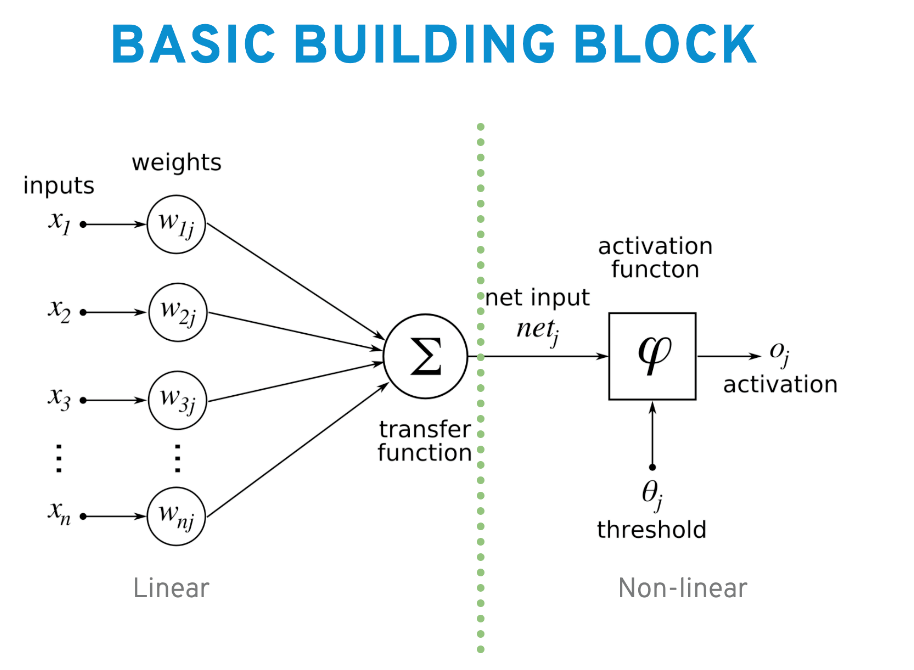
In practice, and without going into too much detail, this results into a basic building block consisting of two parts:
- a linear part;
- a non-linear part.
The linear part is multiplication and addition, starting from the bits of your image or words from your texts, these value will be multiplied by a set of numbers (weights) and then summed up together.
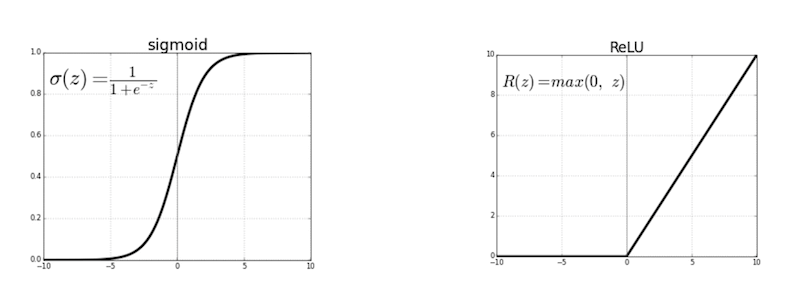
Secondly, the non-linear part makes use of an ‘activation function’, which transforms an input non-linearly. Although, that might sound scary, below are two examples of popular activation functions.
The one on the right (ReLU) can be translated to:
- negative input: output ‘0’;
- positive input: output the input.
Not scary at all…
Note: Granted, this is a bit technical, but do not worry, you do not need this kind of specialized knowledge to use the current state of the art. However, it might later help you understand what is really going on, and, most important, it should show you there is little magic involved.
Now, if we stack a lot of these building blocks (multiplication/addition + non-linear) on top of each other, we get what is called: “a neural network”.
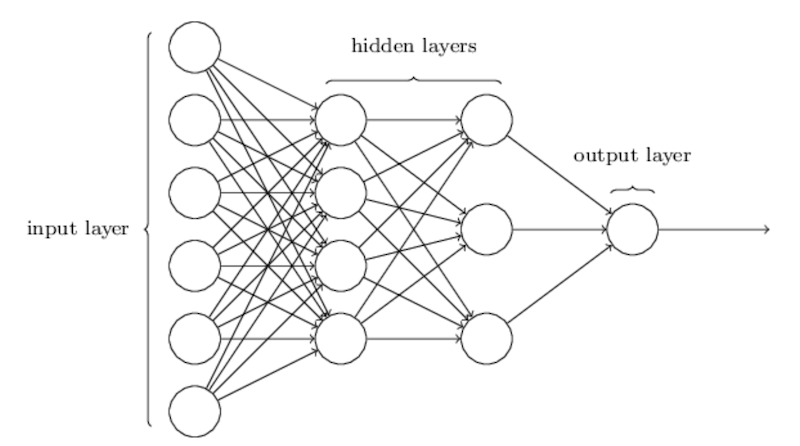
The “input layer” is the inputs we described above (image, text…), the output layer is the prediction the network makes (e.g. “spam or not”). In between we find the “hidden layers” where the computation is going on.
Neural networks have existed for a long time, but due to data and compute limitations, only small stacks of building blocks could but put on top of each other, resulting into what is called “shallow” neural networks, with limited performance.
In essence
Machine Learning gives the computers the ability to learn (gain experience) from data to perform a certain task without explicitely being told what to do.
Where to next
This post is part of our “Artificial Intelligence - A Practical Primer” series.
Or have a look at: