Introduction
So, why is AI working now?
Artificial Intelligence has been around since the 1940-50’s and has gone through a number of ‘golden years’, all followed by an AI winter.
So why should now be any different?
In this article we will discuss the four reasons why AI is now able to achieve production ready results.
1. An abundance of data
Firstly, there is an abundance of data: images, text, structured data…
And not only data on the internet, but companies and even individuals have or can easily gather, manage and store a lot of data.

But why is that important?
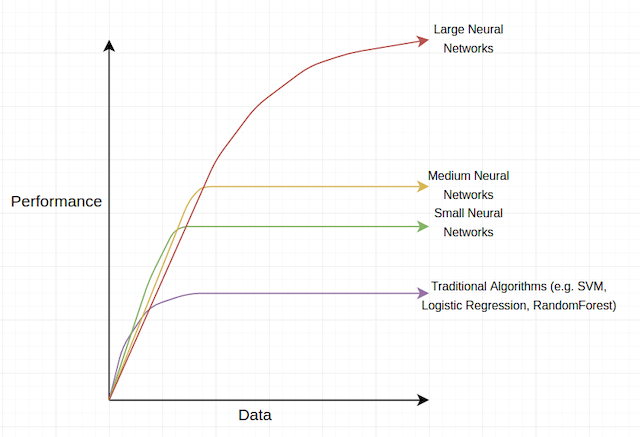
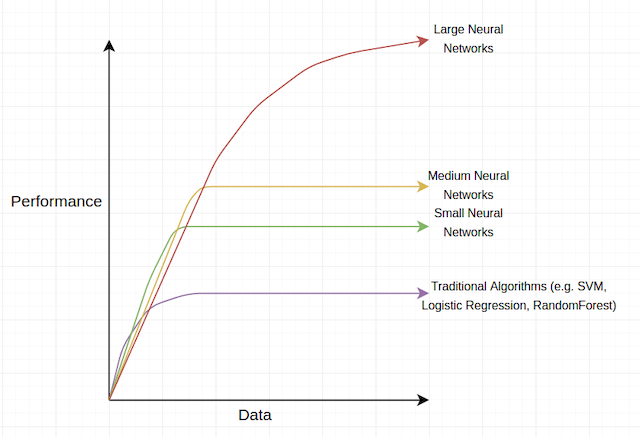
We see that for deep (large) networks, the more data samples they see, the more accurate they become.
2. Processing Power
Remember that deep learning models consist of building blocks that do a lot of:
- multiplications
- additions
- taking the maximum
stacked one after the other.
If we want to do that on a lot of data in parallel, the fastest way to do that today is on a GPU, which have become increasingly powerfull in recent years.
In the image below we specifically chose an NVidia GPU, because these are the only ones currently supported by all the deep learning frameworks.

For completeness, a lot of companies are working on either creating AI specific hardware, or are working on making current models useable on their existing hardware.
3. Algorithm advances
Although most concepts that underpin these technologies have been developed since the 1950’s, we see a lot of recent (since 2012) advances in algorithms, architectures and new techniques keep coming out on a regular basis:
- Optimizers (Adam, Ranger, …)
- BatchNormalization
- ResNets, EfficientNets, …
- Activation functions (Swich, Mish, …) …

At this point, this might sound a bit overwhelming, but without going into too much technical detail here, these advances mostly focus on three aspects:
- train better models
- faster
- with less data.
4. Frameworks
If you read the AlexNet paper from 2012, you will find that the authors had to jump through a number of hoops to train ImageNet on their GPUs.
In recent years, the number of deep learning frameworks has significanly increased, making it easier for researchers and developers to train deep learning networks.
These frameworks come in a variety of flavors depending if you want to have access to low level operations (matrix operations, hardware access), or if you just want to solve a particular high level AI application without wanting to know all the details.

Additionally, it has become easier (although this might still require some effort) to run your networks not only on bulky servers, but also on mobile or smaller, local devices.
In Essence
AI is becoming more capable of solving actual real world problems, because of four driving forces:
- an abundance data
- an increase in processing power
- advances in the underlying algorithms
- accessible frameworks in a variety of flavors.
Where to next
This post is part of our “Artificial Intelligence - A Practical Primer” series.
Or have a look at: