Artificial Intelligence - A primer
By Jan Van de Poel on Jan 5, 2025
Introduction
Artificial Intelligence (AI), machine learning (ML), and deep learning (DL) seem to be taking the world by storm and are revolutionizing industries and transforming the way we live and work. With their potential to create previously unimaginable digital solutions, it’s no wonder they’re generating immense excitement and curiosity. But amidst the hype, questions arise: will AI truly disrupt every sector, or is this just a passing trend? Will established businesses be replaced by tech giants or innovative startups?
In this primer, we’ll cut through the noise and provide a clear understanding of AI, ML, and DL. We’ll explore what these technologies are, their practical applications, and why they’re gaining traction now. By separating fact from fiction, we’ll also debunk common myths surrounding these technologies.
Our introduction will cover:
Foundational concepts: A straightforward explanation of AI, ML, and DL
Real-world examples: Practical applications demonstrating the potential of these technologies
The ‘why now’ factor: Understanding the current landscape and what’s driving adoption
Myth-busting: Separating reality from hype to give you a clear understanding of what AI, ML, and DL can truly achieve
We keep our head in the clouds…

…but our feet on the ground.

Definitions
Before we can go any further, it is important to know what we are talking about exactly. Sometimes it seems like Artificial Intelligence, Machine Learning and Deep Learning can used interchangeably. However, there is a clear way to define each of them.

Artificial Intelligence
Artificial Intelligence (AI) isthe broad family of technologies performing tasks normally requiring human intelligence.
So what does that mean?
Computers are amazing at processing a lot of data. Take a spreadsheet for example. Computers are capable of storing, manipulating, visualizing and linking an insane amount of data points and formulas, instantly churning out results that are impossible for humans to calculate or memorise.

Another notable demonstration of computing power is the seamless rendering of complex websites and web applications in mere milliseconds. Web developers can attest that predicting exactly how their creations will appear on various devices - from desktops to tablets to mobile phones - can be a challenging task, given the intricate dance of HTML, CSS, and JavaScript code. Moreover, understanding compressed code for web applications can be a challenge in itself. Nevertheless, computers effortlessly interpret and display these complex digital applications across diverse screens and devices, showcasing their remarkable processing capabilities.

Despite their immmense processing power, computers have long struggled with a task that comes naturally to humans: recognizing and identifying various animals in an image. Even when we see them from a different or unusual angle, we can usually tell what animal it is. When we do not know one of the animals in the picture, it takes no effort for humans to learn for example that the bird is a ‘King Fisher’. Next time you see that bird, you will remember it is a ‘King Fisher’, even only after seeing it once. This ability to learn and remember new information with remarkable ease has been a significant challenge for computers to replicate.

Machine Learning
Machine learning is a subset of techniques in the field of AI where:
Computers learn without being explicitely programmed.
In ’traditional’ programming, a programmer writes the software according to what needs to be done. A program is carefully crafted to handle data through a set of steps, checks, calculations, and visualisations to solve a particular problem. Suppose you h

As a concrete example, let us look at a money transfer in a banking app. The programmer knows exactly how to authenticate the user, fetch its accounts, check the balance and transfer a given amount on a certain date to another account…
The data being used reaches from user credentials, to account data, amounts etc…

In the machine learning approach, however, we will use the data and the matching results, and by learning the relationships between data and results,try to produce a ‘program’ that is able to predict the results from inputs it has not seen before.

As a more formal defition, we use the one below:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, as measured by P, if its performance at taksks in T, as measured by P, improves with experience E.
To be honest, I had to read that definition a couple of times before it started to make sense.
To make it more digestible, we will have a look at two examples:
- Playing checkers

- T = The task of playing checkers.
- E = The experience of playing many games of checkers.
- P = The probability that the program will win the next game.
- Recognizing cats and dogs

- T = The task of recognizing cats and dogs in pictures.
- E = The experience of looking at a lot of pictures.
- P = The probability that the program will identify a cat or dog in a picture.
It boils down to: the more the computer looks at cats/dogs or plays checkers, the better it should become.
In machine learning, two of the most common applications are classification and regression.
In regression we try to predict a value giving a number of inputs. For example:
- given the day of week, temperature, and chance of rain: how many ice creams will be sold?
- given the size, location, and type of real estate: how much is it worth?
- given the time of day and type of post: how many likes will a social media post receive?
In classification we try to predict the class an input or set of inputs belongs to. For example:
- is an incoming email spam or not?
- is a credit card transaction fraudulent?
- is tumor malginent or benign?

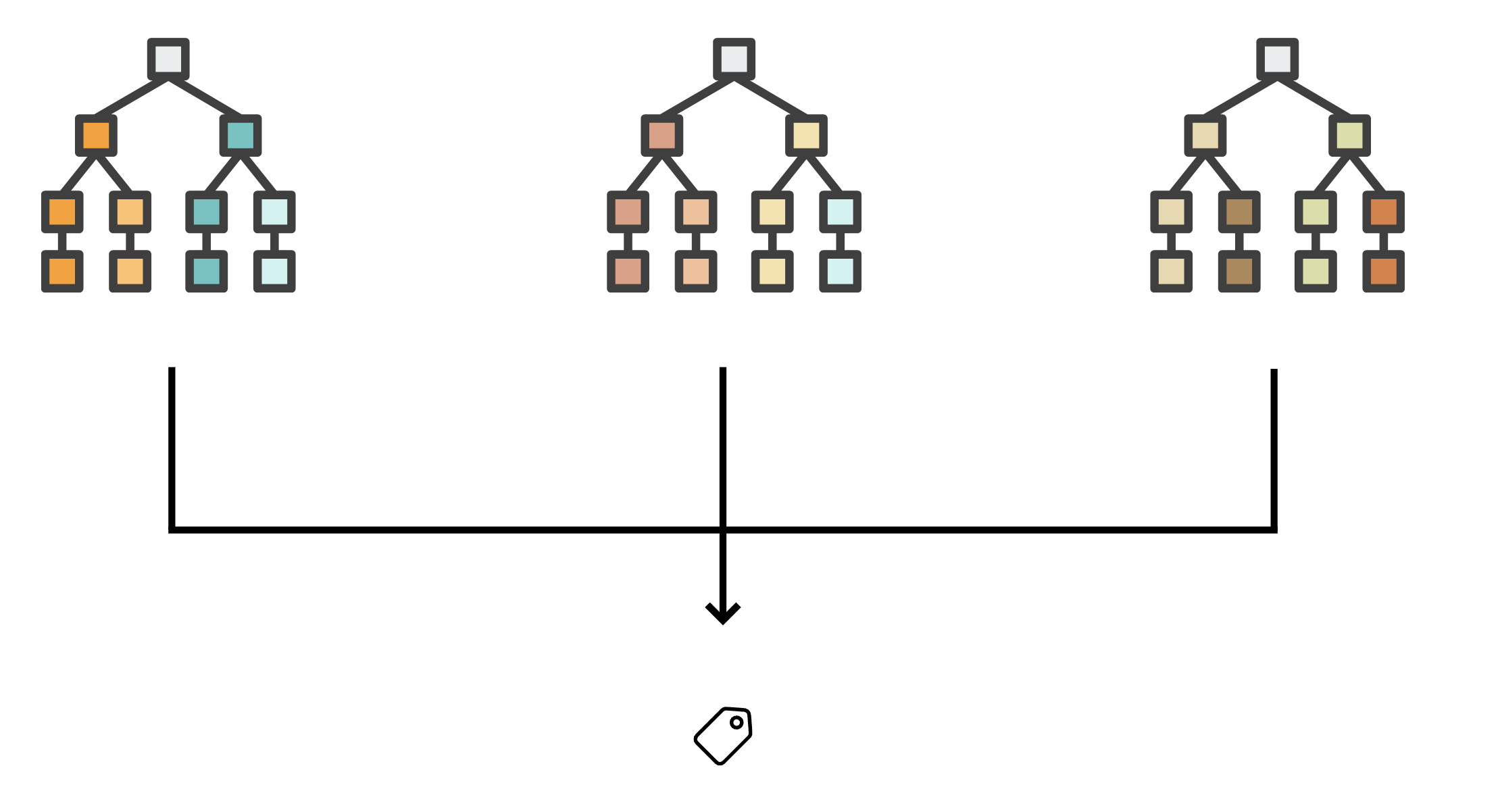
One way to classify inputs is to create a decision tree, which, by using a set of “if-then-else” evalutions, guides you to which class an input belongs. But remember, instead of a human trying to figure out how to construct the decision tree, in machine learning we use the example inputs and outputs to automatically create the best tree for us.
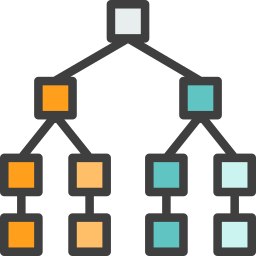
If we combine a number of decision trees, we get what is known as a “Random Forest”. We simply use multiple decision trees to make a suggestion for the output (class or value) and in the final step we use a way (“voting”, “averaging”,…) to combine the results of individual trees to one final output.
A technique that won a lot of attention the last few years - although the idea has been around for decades - is “neural networks”, which in essence builds a mapping from inputs
- an image
- text
- numerical data
to outputs
- “malignent” or “benign”;
- “spam” or “not spam”;
- 74 (ice creams sold).
In a lot of introductions to “neural networks” you will find they are modeled after the brain
which consists of a lot of neurons:
However the main - and mostly singular - similarity is that they both take:
- take in inputs;
- do some form of processing;
- produce an output.
In practice, and without going into too much detail, this results into a basic building block consisting of two parts:
- a linear part: using multiplication and addition;
- a non-linear part: e.g. taking the max of 0 and the input.
In that is about half of the mathematical complexity that goes into building these neural networks.
Deep Learning
Deep learning is the basis of most AI news and updates these days and is in itself a subset of machine learning.

Computer Vision
To understand what it is and how it works, we will discuss some examples, starting with computer vision.

We start our journey with ImageNet which is both a dataset as well as a competition (more on that below).
The dataset consists of ~1.1 million labeled images, spread over 1000 different classes (“speedboat”, “ballpoint”, “stove”, “trench coat”, “trombone”…). Click here for a full list of all the classes.

Between 2010 and 2017, there was a yearly competition (ImageNet Large Scale Visual Recognition Challenge - ILSVRC) that brought researchers worldwide together to compete in predicting the class that was depicted in an image.
The graph below shows the winner results from 2011 to 2016.
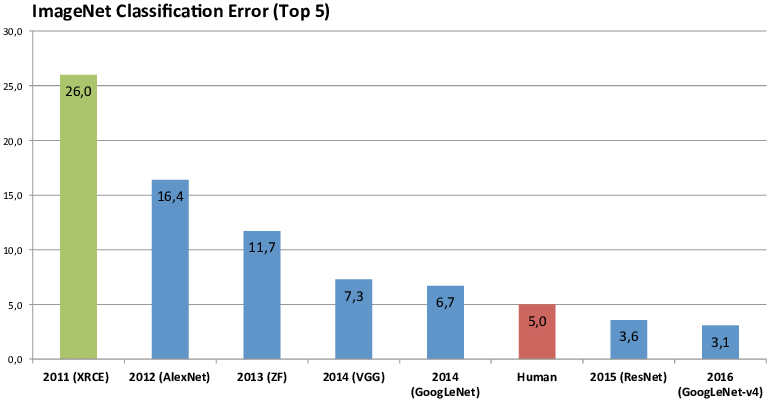
In 2011, the winner was able to predict the correct class for an image in about one in four (~26%). (Top-5 prediction means the correct answers was in the top-5 suggestions from “the algorithm”).
Important here is that this was a ’traditional’ computer vision approach, handcrafting a lot of functionality to detect specific traits (for examples to detect edges).
In the 2012, an entry named “AlexNet” beat the competition hands down, improving accuracy with about 10% over the previous year. What is interesting about this approach is that is does not contain any specific logic related to the classes it was trying to predict. This is the first time deep learning made its way onto the scene.
The years after that, all winners were using deep learning to keep significantly improving the state of the art.
In 2015, it even started beating ‘human level’ performance on ImageNet. The picture below gives you an example of how you can interpret that. Can you easily identify pug vs cupcake?

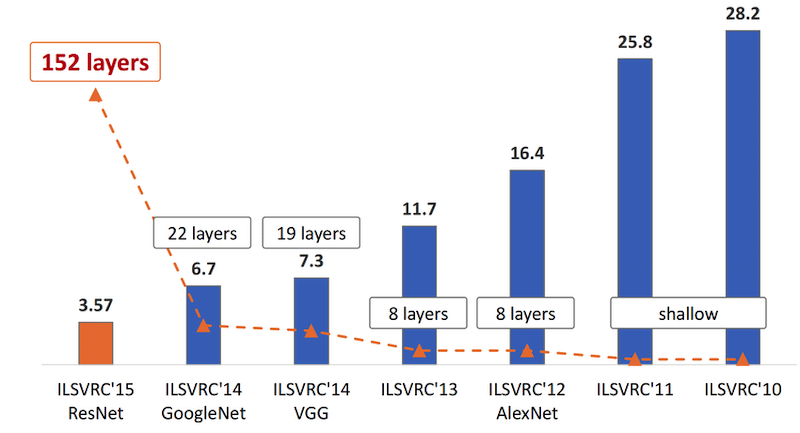
If we think back to stacking those building blocks, we can see that over the years, there are increasingly more “layers” in those networks, which is where we get the name “deep” learning from. (note the picture below in reverse chronological order)
In traditional machine learning, experts use their knowledge and time to craft a set of features that can be extracted from the input, and can be used to train a classification network to produce an output.
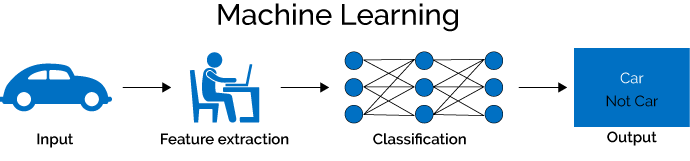
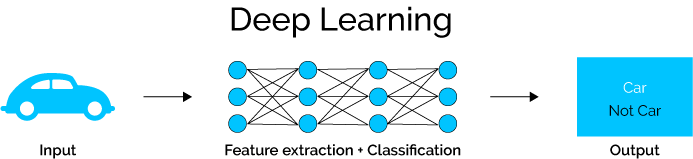
If we compare that to how deep learning works, we see that deep learning takes care of both feature extraction and classification.
In computer vision, we distinguish a set of different applications.
Classification tells you what class is in the images.

Classification and localization tell you which class it is in the image and where that class is by predicting the bounding box.

Object detection makes a prediction for all classes it thinks are in the image, together with their bounding box.

Scene segmentation predicts the classes in the picture as well as the countour of that object. In practice this comes down to predicting a class for every pixel of the image.

Natural Language Processing(NLP)
Natural language processing is the ability for computers to handle written text. Computers have long been good in storing, editing and displaying text, but have only in recent history been really able to be process text with results similar or even better than humans.
Probably the most famous examples is email classification. Given an incoming mail, should this be marked as spam or be allowed to move the user’s inbox?

More generally, you can apply text classification to a broad number of topics:
- spam or not;
- sentiment analysis;
- topic detection;
- email routing;
- …
Why now?
So why is this working now?

Data, data, data
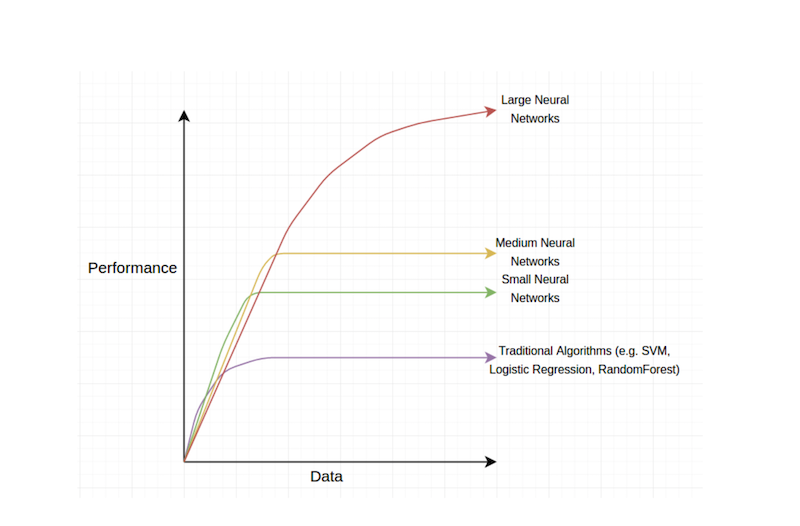
First of all, the amount of data we have at our disposal. In contrast to humans, computers need to look at a lot of examples (we will nuance this below) to learn concepts. That data was not around in the beginning of the 2000’s but now it is…

The reason why data is so important, is that deep learning algorithms get more data hungry, the larger/deeper they get, and we have seen that deeper networks tend to perform better.
GPU hardware
Secondly, the availability of hardware. Deep neural networks, in essence, consist of a lot of multiplications and non-linearities, and at training time they will look at a lot of data, which requires powerfull computers, more specifically graphical cards, as they tend to offer the best results. Note that some companies are also creating AI-specific hardware to increase performance even further.

Algorithms
Although the ideas existed in the 1950’s and most of the core algorithms stem from the 1980’s, some recent breakthroughs in supporting networks getting deeper have contributed to deep learning becoming the workhorse of AI.
The details of these algorithms are far beyond the scope of this text.

AI Software Frameworks
Fourth and final factor contributing to the current success of AI, and often overlooked, are the frameworks to implement it, allowing developers to implement algorithms without having to write everything from scratch, or even know all the details. The frameworks offer a valuable layer of productivity abstraction.

Some hardcore myths
There is a lot of misticism when it comes to AI. In this section, we try to debunk some of them.
PhD requirement
Contrary to popular belief, you do not need a PhD to apply AI and deep learning today. There are a lot of resources, frameworks and even pretrained models out there to get you going. If, however, you want to get into reseach, muchlike in any field, a PhD might be a good idea.

Replaces domain experts
From experience it is usually the opposite. Deep learning is really goed in learning to map inputs to outputs but we still need people who understand the domain very well, to get the correct data to learn from and to see if the results being produced are actually any good.

Massive amounts of data
Above we mentioned that deep learning models are data hungry, and the more data they see, the better they get. Luckily, there are ways to reuse a lot of knowledge and tweak it to our benefit, giving us excellent results without needing 1000’s of images.

GPU galore
GPUs are used to train your network but unless you are into researching the latest and greatest, you can easily get started with two or even one… As someone once said, “if you have been collecting and cleaning your data for a couple of weeks, who cares if your algorithm takes 20 minutes longer to train”.
The elephant in the room

Large Language Models (LLMs)
Of course, there is an elephant in the room here. Up to now, we have only discussed what is currently seen as ’traditional deep learing’: taking a lot or a diverse set of inputs and generate a small output such as a label or number. Since a couple years now - as you probably know - a newer form of AI: Generative AI or GenAI, which has brought AI mainstream, making it more accessible, powerful and useful (in certain domains).
On November 30, 2022 OpenAI released ChatGPT to the public. A simple chatbot that anyone could interact with, powered by a technology called Large Language Models or LLMs. These language models are in essence ’next word predictors’, meaning that given some input text (or images for Vision Language Models - VLMs) they will predict the next set of most likely next words. This makes them extremely useful for chat applications, where you can interact, ask questions or give instructions.
The most cited drawback from a users perspective is probably that LLMs tend to ‘hallucinate’. By way of how they work, they will predict the next set of most likely words, regardless of whether those are factually correct. One way of mitigating this, is by giving the model extra context in the form of specific instructions “Rewrite my text”, “Summarize this text”, “Use only the information in this document”, …
Applications of LLMs
Chat
As mentioned above, chat is probably the way most people use LLMs these days, from asking simple questions or providing a meal plan, to making it almost a proper work colleague or sparring partner to boost their productivity.

Retrieval
Often people of companies want to use these LLMs to chat with their data: structured data or all of their documents. However, when chatting with these models, the size of the input text (context) is limited - most models will give you a number of context length, the number of tokens you can supply as input.
This problem is addressed by a technique called Retrieval Augmented Generation (RAG). Meaning that instead of supplying all of your documents as input to the LLM to answer your question, you only supply the information that is matched with your question, and let the LLM form its answer based on that information.

Search
Extending Retrieval to span the entire internet and combining that with powerful LLMs, might give way to a new way we search and interact with the internet. Tools such as Perplexity or SearchGPT are easily accessible.

What’s next?
AI Agents
2025 will likely be the year where a lot of companies and people will talk and experiment with agents. You can already hear the AI Agent buzz when you listen o or read any tech publication.

Now there are two types of AI agents that are used interchangeably, but which are distinctly different: AI workfklows and AI Agents.
AI Workflows
Firstly, an AI workflow can be seen as a structured sequence of connected steps and processes that combine different AI components to solve complex problems or automate tasks.

Imagine you have a way to capture sound (meetings, customer calls, …) and that sound is transcibed to text via a speech-to-text model. You pass that text snippet to an LLM to correct mistakes or correct domain specific grammar, and next you extract structured information or sentiment, which in turn gets stored in a dataset or is integrated in a part of the business.
AI Agents
AI agents on the other hand are far more flexible. You give them a task to solve and the AI agents decided what needs to be done, which sources need to be queried (data, documents, the internet, …) and which agents are needed to get the result.

By simply describing the goal, the AI agents will take care of it.
Reasoning
In line with AI Agents, a new paradigm of ‘reasoning’ has emerged. While online activity and chat have always been about speed (next to quality of course), more providers are now adding models that excell at reasoning, taking (far) more time to get to answer for more complex problems.

ANI, AGI, ASI?
Everything we have discussed up to now is generally seen as Artificial Narrow Intelligence (ANI). Over the coming years, the capabilities might improve exponentially leading what is called Artificial General Intelligence (AGI) or even Artificial Super Intelligence (ASI).

Artificial Narrow Intelligence (ANI)
This refers to AI systems designed for specific tasks, like playing chess, image recognition, or language translation. Current AI systems, including myself, are ANI - we excel at particular domains but lack general-purpose intelligence. ANI is already having significant impacts across industries through automation, decision support, and specialized problem-solving.
Artificial General Intelligence (AGI)
This describes AI systems that can match or exceed human-level intelligence across virtually any cognitive task. AGI would be able to transfer knowledge between domains, learn new skills independently, and demonstrate general problem-solving capabilities comparable to humans. While significant research is ongoing, we haven’t achieved AGI yet. Its development would likely transform society fundamentally through automation of complex cognitive work and acceleration of scientific/technological progress.
Artificial Super Intelligence (ASI)
This refers to AI systems that would significantly surpass human intelligence across all domains. ASI would be capable of recursive self-improvement and could advance technology and scientific understanding far beyond human capabilities. This is currently the most speculative category.
In closing
There has been an undeniable progress - to say it lightly - in the research and application of AI over the last few years, and things seem to be mostly accelerating.
But remember, we need to keep our feet on the ground.
And little understanding goes a long way.
The more we understand, the easier it will be to benefit from AI, because in the end, that is where its magic lies.
We look forward to seeing you in the course, so we can learn, explore and share together.